The recent service disruption in the AWS Middle East (Bahrain) region served as a stark reminder for Cloud Architects: Availability Zones are not enough. While AWS design principles emphasize Multi-AZ for high availability, true business continuity requires us to look beyond regional boundaries.
In this deep dive, we explore how to achieve Regional Resilience using the AWS Well-Architected Reliability Pillar. We will break down three distinct architectural patterns, their recovery metrics, and the precise switchover logic required to survive a regional blackout.
Pattern 1: The Multi-Region Enterprise Stack
For mission-critical enterprise applications, the goal is structured failover of stateful workloads. This architecture balances cost with a robust recovery sequence.
Tech Stack: EKS + RDS + Route 53 ARC
Primary Strategy: Active-Passive (Warm Standby)
Traditional DNS failover is often bottlenecked by TTL (Time-to-Live) propagation. By the time the world knows your region is down, 5 minutes of revenue are gone. To solve this, we introduce Route 53 Application Recovery Controller (ARC).
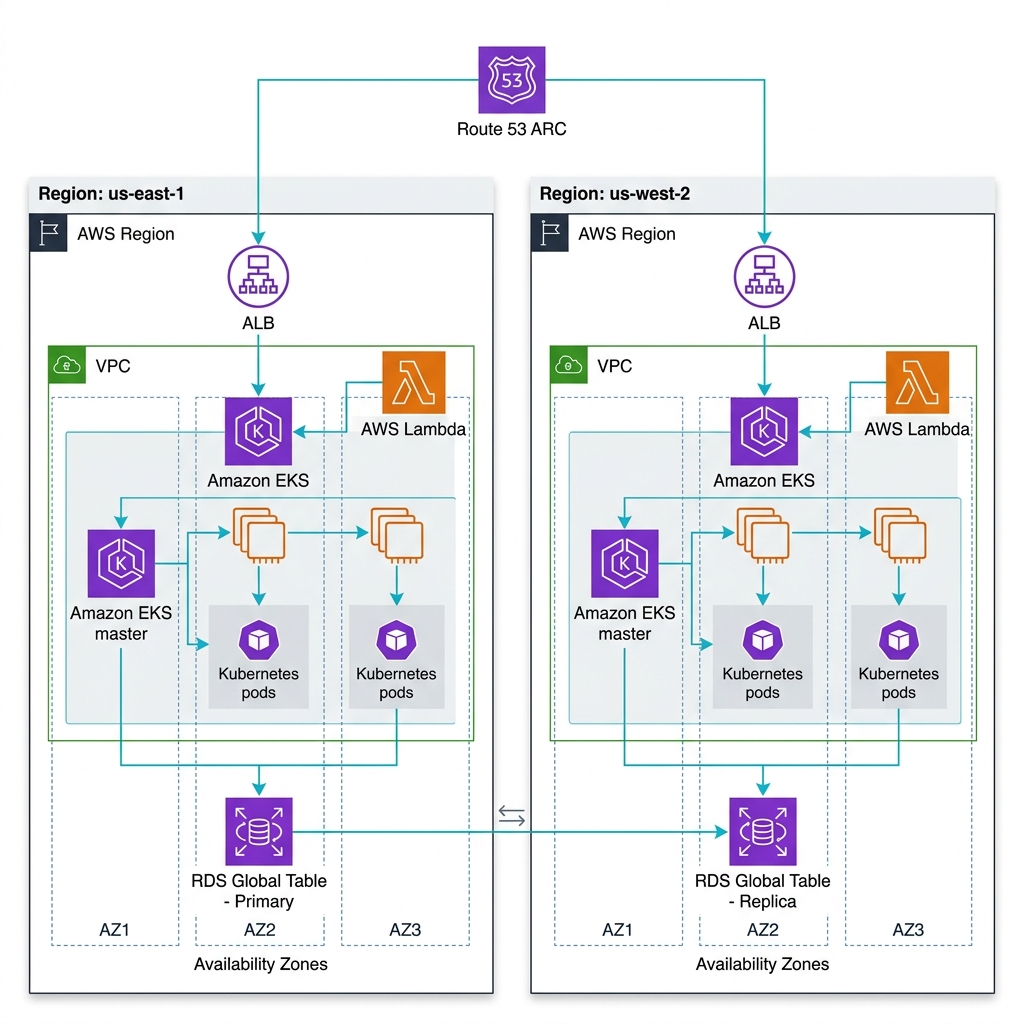
The Switchover Logic:
- Health Monitoring: ARC Readiness Checks continuously audit the secondary region to ensure EKS node groups have reached desired capacity and secondary RDS replicas are healthy.
- Database Promotion: Trigger an RDS Global Database failover to promote the secondary replica to Primary. This happens in under 60 seconds.
- Data Plane Toggle: Update the ARC Routing Control. Unlike a standard DNS update, ARC Routing Controls use a highly available cluster of endpoints (data plane) to flip the switch with near-zero latency.
- GitOps Sync: ArgoCD ensures the application manifest in the secondary region matches production perfectly.
Pattern 2: The Serverless "Always-On" Active-Active
If your application cannot afford even a 5-minute RTO, a serverless Active-Active architecture is the gold standard. Every request is routed based on the closest healthy region.
Tech Stack: SAM + API Gateway + DynamoDB Global Tables
Primary Strategy: Active-Active (Multi-Region)
The beauty of this stack lies in DynamoDB Global Tables. It provides multi-master replication, allowing writes in any region. When Bahrain (me-south-1) goes silent, Route 53 latency-based routing simply stops sending traffic there.
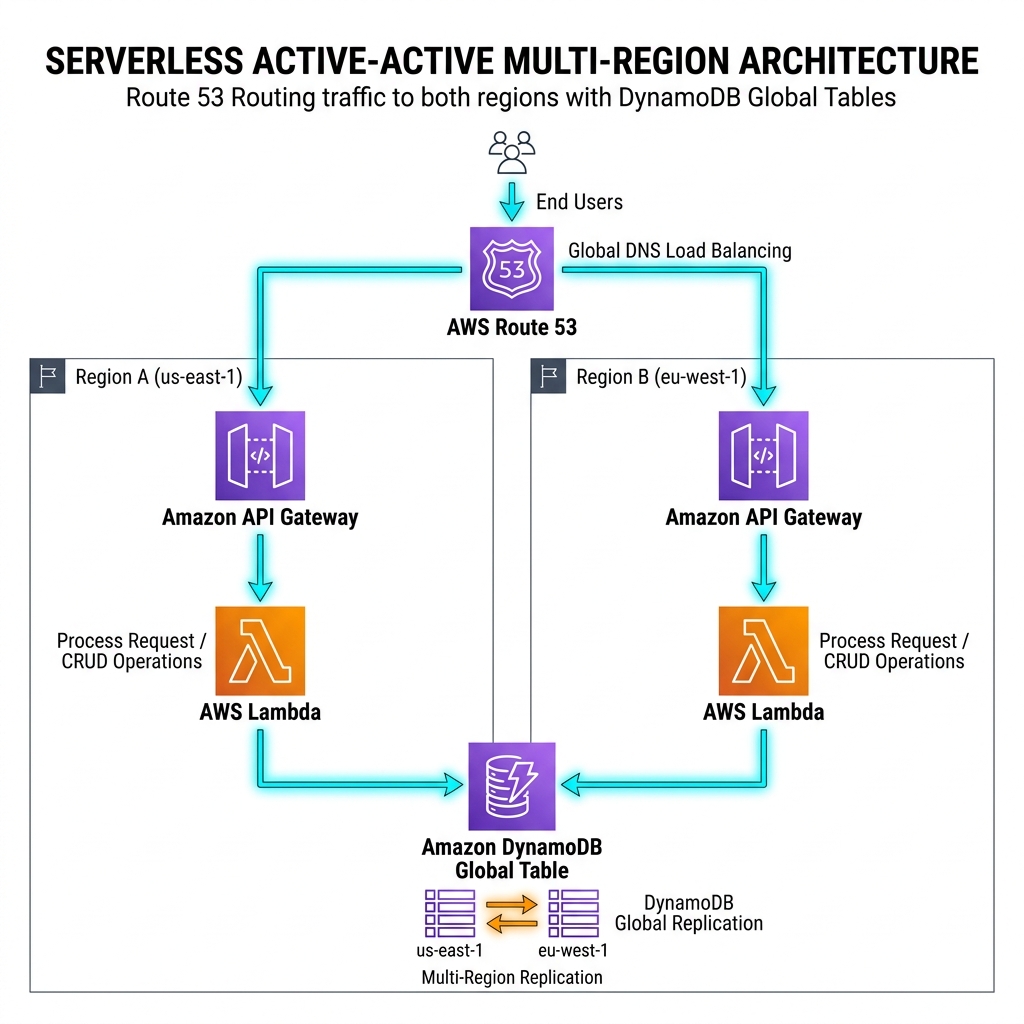
The Switchover Logic:
In this pattern, "switchover" is largely automated and transparent:
- Route 53 Health Checks: API Gateway endpoints are monitored via Route 53 health checks. If the endpoint fails to respond (5xx or connection timeout), it is pulled from the latency routing pool.
- Global Table Replication: Since data is already replicated asynchronously, the user's next request in the secondary region (e.g., Ireland or UAE) finds their state already waiting for them.
Pattern 3: The Resilient AI/ML Pipeline
As GenAI moves to production, we must ensure foundation models and vector stores stay online. An AI outage is often more complex because it involves massive data replication and model availability.
Tech Stack: Bedrock + S3 CRR + OpenSearch CCR
Primary Strategy: Active-Passive with Inference Overflows
For the AI layer, we use Amazon Bedrock Cross-Region Inference Profiles. This allows AWS to automatically manage model traffic across a group of regions, ensuring that if one region's GPUs are saturated or offline, your LLM request is fulfilled elsewhere.
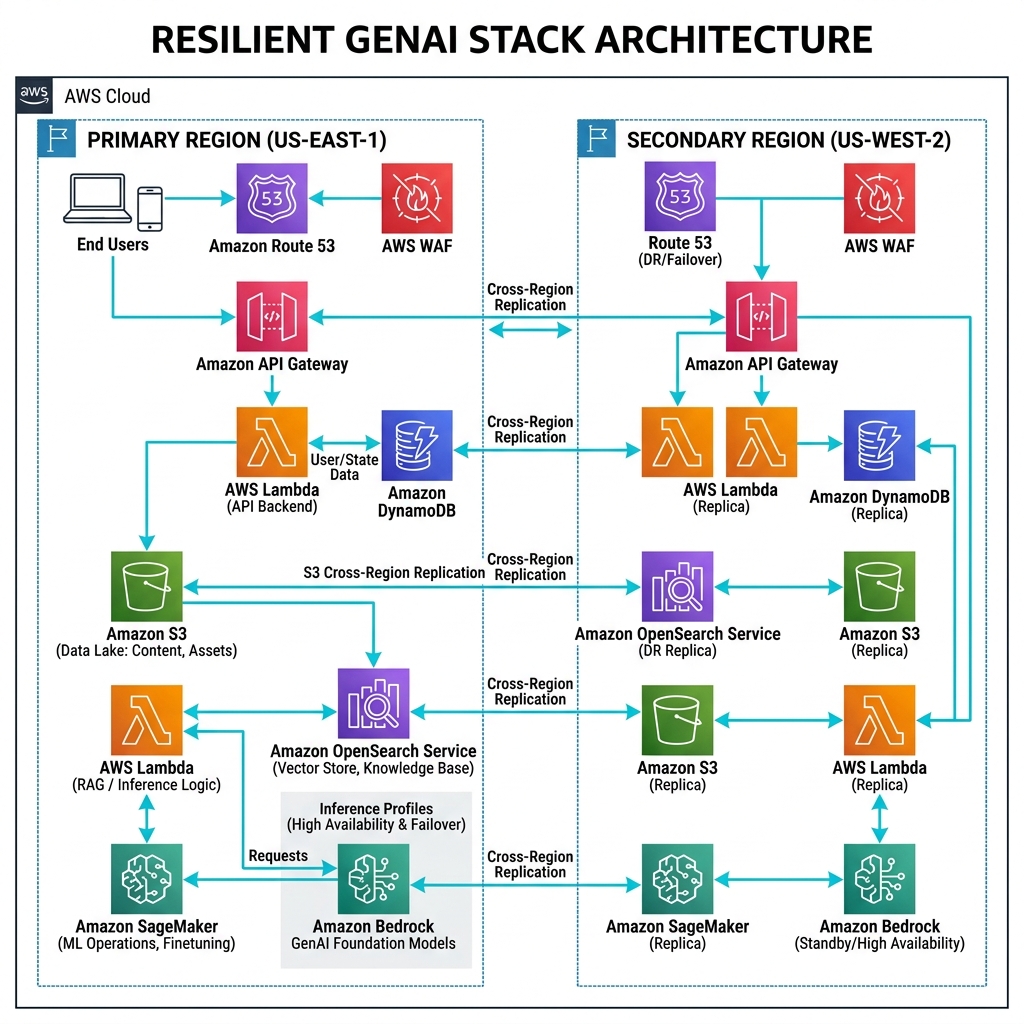
The Switchover Logic:
- S3 Cross-Region Replication: Logs, training prompts, and fine-tuning datasets are replicated instantly.
- OpenSearch CCR: Use Cross-Cluster Replication to sync your vector indices from the leader (primary) to the follower (secondary).
- The Reveal (Manual Promotion): During a regional failure, you must call the
_stopreplication API on the follower OpenSearch index to make it writable. Once promoted, the application layer is pointed to the new OpenSearch cluster. - Bedrock Managed Failover: No action required. Bedrock Inference Profiles handle the rerouting of model calls at the infrastructure level.
Conclusion: It’s Not IF, But WHEN
Regional outages are rare, but their impact is existential. Architecting for regional resilience requires a shift from "Infrastructure as Code" to "Recovery as Code." By implementing Route 53 ARC, Global Databases, and Bedrock managed profiles, you turn a potential catastrophe into a managed event.
Remember: A disaster recovery plan is only as good as the last time you tested it. Run your Game Days, break your regions on purpose, and architect for the day it stops working.
Interested in a Resilience Audit for your AWS infrastructure? Let's talk.